Quick Reference: CI/CD
Quick Reference: CI:CD - Course Introduction and Goals.webarchive
CI/CD Overview
What is CI/CD?
CI/CD, or Continuous Integration/Continuous Delivery, refers to the process of developing and delivering software in short, frequent cycles through the use of automation pipelines. By automating the building, testing, and deployment of code, development teams are able to deliver releases more frequently and reliably than the more manual processes that are still prevalent across many data engineering and data science teams.
Continuous integration begins with the practice of having you commit your code with some frequency to a branch within a source code repository. This is known as version control and is most frequently done with the open-source tool, git. Each commit is then merged with the commits from other developers to ensure that no conflicts were introduced. Commits are further validated by creating a build and running automated tests against that build. This process ultimately results in an artifact or deployment bundle that will eventually be deployed to a Databricks Workspace.

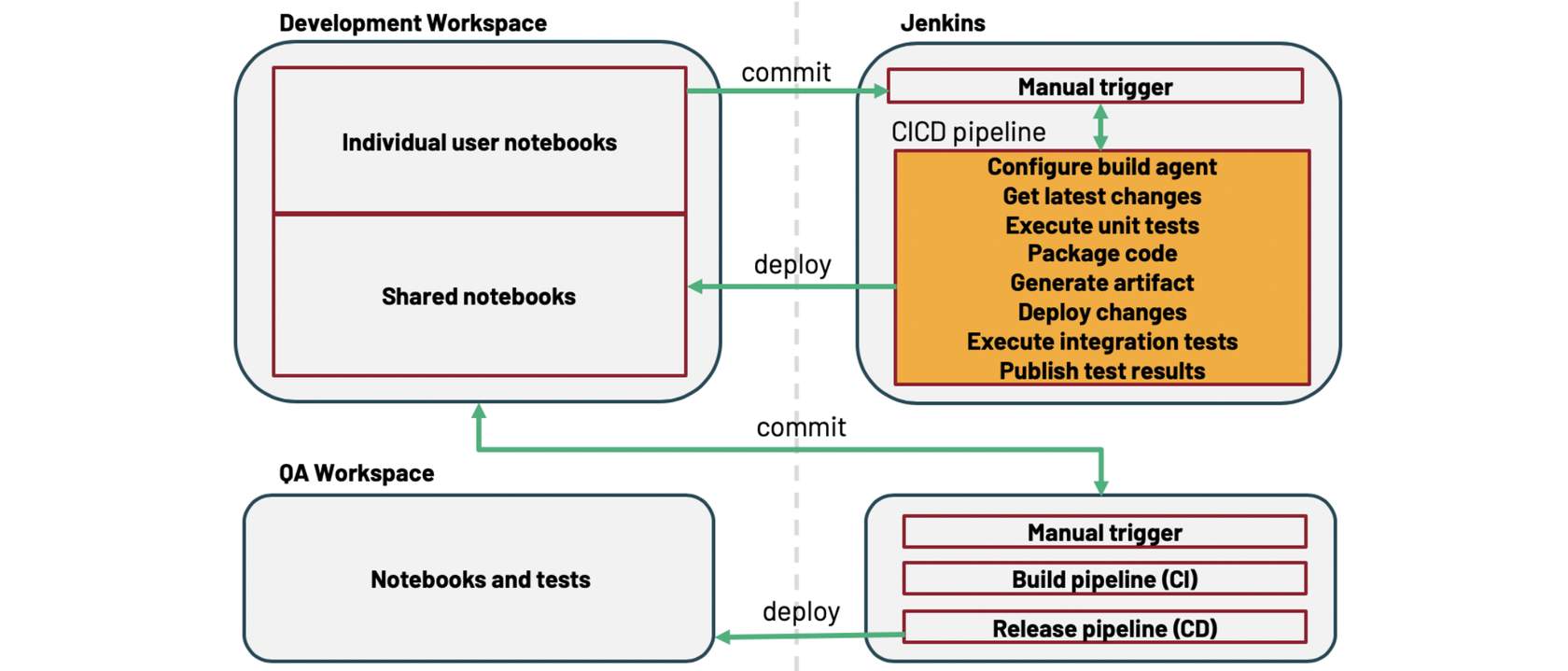
Stages to automate a CI/CD pipeline
The image below shows an example of how an automation agent works to automate a CI/CD pipeline on Databricks. As seen in the image, there are eight stages in automating a CI/CD pipeline: Configuring the automation agent (in this case, Jenkins), getting the latest changes to your code, executing unit tests, packaging code, generating artifacts, deploying artifacts, testing notebook code using other notebooks and publishing test results.
Deciding on a CI/CD Strategy
One of the first steps in designing a CI/CD pipeline is deciding on a code commit and branching strategy to manage the development and integration of new and updated code without adversely affecting the code currently in production. Part of this decision involves choosing a version control system to contain your code and facilitate the promotion of that code.
When deciding on a CI/CD strategy to use for Databricks, note that Databricks supports integrations with GitHub and Bitbucket, which allow you to commit notebooks to a git repository. If your version control system is not among those supported through direct notebook integration, or if you want more flexibility and control than the self-service git integration, you can use the Databricks CLI to export notebooks and commit them from your local machine. This script should be run from within a local git repository that is set up to sync with the appropriate remote repository. When executed, this script should:
- Check out the desired branch.
- Pull new changes from the remote branch.
- Export notebooks from the Databricks workspace using the Databricks CLI.
- Prompt the user for a commit message or use the default if one is not provided.
- Commit the updated notebooks to the local branch.
- Push the changes to the remote branch.
The following script performs these steps:
git checkout <branch>
git pull
databricks workspace export_dir --profile <profile> -o <path> ./Workspace
dt=`date '+%Y-%m-%d %H:%M:%S'`
msg_default="DB export on $dt"
read -p "Enter the commit comment [$msg_default]: " msg
msg=${msg:-$msg_default}
echo $msg
git add .
git commit -m "<commit-message>"
git push