Week 2: Recommender Systems with Cloud SQL and Spark
This module is on performing product recommendations using Cloud SQL and Apache Spark. Cloud SQL, which is a managed relational database, and Cloud Dataproc, which is a managed environment on which you can run Apache Spark
Introduction to Machine Learning
The core pieces of a recommendation system are: data, the model, and infrastructure to train and serve recommendations to users. Our data set for this scenario will be housing rentals that we want to recommend to our users based on their preferences. We'll use a machine learning model to make these recommendations..
Hard-coding logic for all these features and different kinds of user segments isn't scalable, and it assumes that we always know the right answer for every scenario. Machine learning scales much better because it doesn't require hard-coded rules. It's all automated. Learning from data in an automated way. Machine learning is this idea that we want to teach the computer using examples, not with rules. Any business application where you have those long switch or case statements or if-then logic manually coded, and you have a history of good labeled data, that is data for which you know a good answer or a bad answer, a history of good labeled data, any such application is a possible application for machine learning.
Challenge: Machine Learning for Housing Recommendations
So how would housing recommendations work in our system? First, we need to ingest the ratings of all the houses that have already been done by our users when we showed them specific houses. So we have to go to an inventory of rentals and ingest the ratings for the houses. These ratings could come from explicit ratings. Maybe we showed the user the house in the past and they've clicked four stars after seeing the house details, or the ratings have come from implicit ratings. Maybe they've spent a lot of time looking at the website corresponding to this property. Then, we'll train a machine learning model to predict a user's rating of every house that we currently have in our listing database. We will then pick the top five rated houses that they haven't already seen.
So how would we predict a user's rating of a house, particularly, if they haven't seen it before. The model is based on two things. It's based on your other ratings, what have you rated other houses, and other people's rating of this particular house. A particularly simple model could be to look at all the users who rated this particular house and find the three users in their list who are most like you, maybe, they live in your country, maybe they have the same age, maybe they went to the same college, find the three users on that list who are most like you. Then, the prediction is the average of those three users ratings. This is not a great model of course. It's too easy to game. Think about what happens if three people gang up together and rate a house, a house that nobody else cares about. So there are only three ratings for this house. So the three closest users are going to be these three people. So for sparse houses, it's really, really, really easy to game. But this idea of using user ratings of a particular house and users like you helps convey the basic premise of how recommendation models work.
So where is the machine learning here? Where's the learning? The model would have to figure out how to find the users who are most like you. How many users to consider. Three users, five users, seven users, how many? And how to weight the different factors such as the overall popularity of the items you have in common and so on. This can be done by seeing what parameters help predict if you intentionally withheld ratings best. So we may have thousands of items and only 2-3 reviews per item. The chances are those reviewers have nothing in common with the user that we want a rating for. So because this rating matrix is extremely sparse, we need to cluster items and users together

Now that we understand the problem and approach, we need to address the last question, the infrastructure question. How often and where will you compute the predicted ratings, and once you have them, once you've computed these ratings, where would you store them? What do you think? How often and where will you compute the predicted ratings? It's not as if rental recommendations have to be updated every time some users somewhere rates a house. We don't need to update the rental recommendations every time a new rating appears in our system. It's probably sufficient if we update the recommended houses for users once a day, maybe even once a week. In other words, this does not need to be streaming. It could be batch.
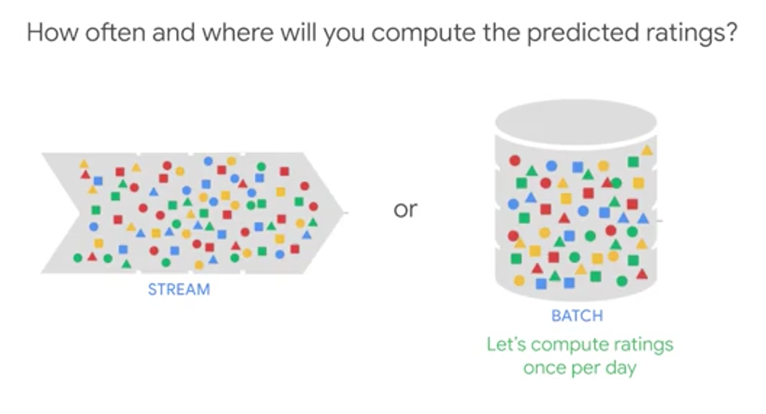
On the other hand, we will probably have thousands of houses and millions of users. So it's probably best that we compute the rating that every user will give every house, we do that computation in a scalable way. We don't want to do it on a single machine, we want to do it in a fault tolerant way that can scale to large datasets. So a typical solution for computation that has to happen over large datasets in a fault tolerant way is to do it in a big data platform like Apache Hadoop. Finally, where will you store the computed ratings? Why would you want to store them? Well, we probably want to power a web application with these recommendations and we don't want to compute recommendations when the user reads a webpage. We want to precompute these recommendations, as we said, it's a batch job. So once a day, once a week, we pre-compute it.
Then, when the user logs on, we want to show that user the recommendations that we precomputed specifically for them. So we need a transactional way to store the predictions. Why transactional? So that while the user is reading these predictions, we can update the predictions table as well. Assuming that there are five predictions for every user and we have a million users, that's a table of just 5 million rows. It's small enough and compact enough that a typical solution for this would be to store the data in a relational database management system, an RDBMS like my SQL.
Migrating a Local Environment to GCP
Of course you want to do that only if the migration can add value. For a housing recommendation model, let's say our data science team already has a working on-premise model using SparkML job on your Hadoop cluster. They're interested in the scale and flexibility of GCP, and they want to do a like- for-like migration of their existing SparkML jobs from on-premises, and they want to do this as a pilot project. We don't need to compute recommendations in real time. So Hadoop batch processing is enough. Here, we'll use SparkML, but instead of doing it on-premises, we'll run the machine-learning job on Cloud Dataproc and store the ratings in an RDBMS in Cloud SQL, because this is a relatively small dataset of five recommendations for every user.
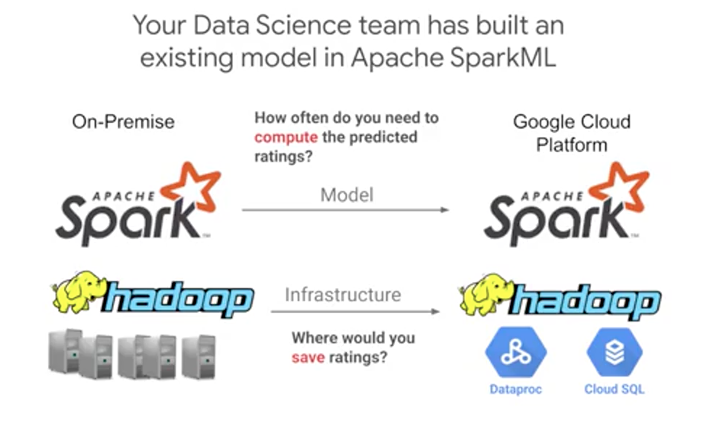
Here's how we decided on using Cloud SQL among the other big data products available for storing our ratings. This is a good reference to follow based on your storage access pattern. We'll cover the solutions in your other scenarios in this course, but briefly, use Cloud Storage as a global file system. Use Cloud SQL as an RDBMS as a relational database management system for transactional relational data that you access through SQL. Use Datastore as a transactional No-SQL object-oriented database. Use Bigtable for high-throughput No-SQL append-only data. So not transactions, append-only data. So a typical use case for Bigtable is sensor data for connected devices for example. Use BigQuery as a SQL data warehouse to power all your analytics needs. So here we wanted a transactional database and we expect to have data volumes in the gigabytes or less, and so hence Cloud SQL.

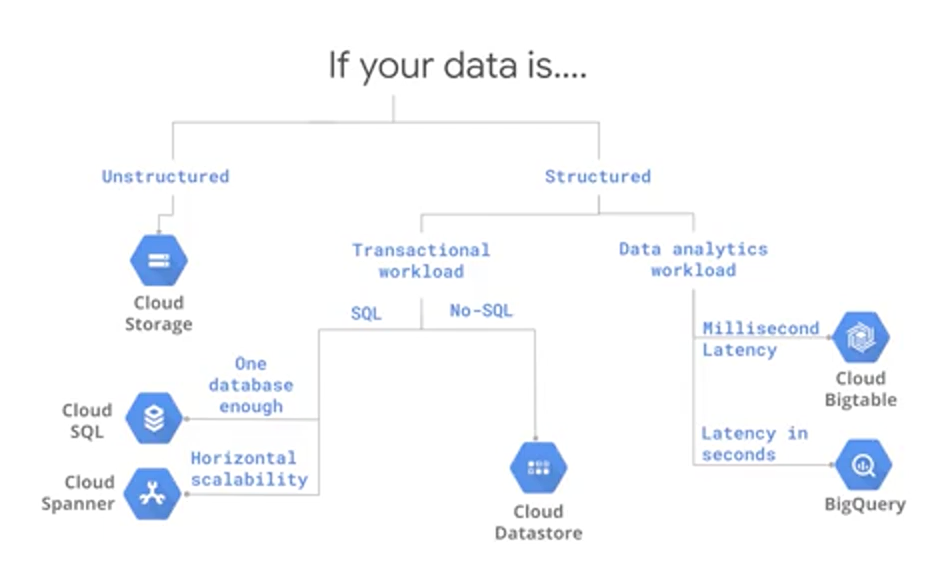
If you're a more visual learner, here is another good map of visualizing where to store your data in GCP. If your data is unstructured, like images or audio, use Cloud Storage. If your data is structured and you need transactions, use Cloud SQL or Cloud Datastore, depending on whether you want your access pattern to be SQL or No-SQL, and by No-SQL we mean a key-value pair. In other words, you'll be trying to search for data based on a single key, use Datastore if you'd be finding data using SQL use Cloud SQL. Cloud SQL generally plateaus out at a few gigabytes. So if you wanted transactional database that is horizontally scalable so that you can deal with data larger than a few gigabytes, or if you need multiple databases so you want them spread globally use Cloud Spanner. So another way to say it as if one database is enough use Cloud SQL. If you'll need multiple databases, either because you have a lot of data or because your application needs to be transactional across different continents, use Cloud Spanner. If your data is structured and you want Analytics, consider either Bigtable or BigQuery. Use Bigtable if you need real-time high-throughput applications. Use BigQuery if you want Analytics over petabyte-scale datasets.
So what's Cloud SQL? It's a Google-hosted and managed relational database in the Cloud. Cloud SQL supports two open-source databases: MySQL and Postgres, and other database solutions. In our case, we'll be using MySQL. One of the advantages of Cloud SQL is that it's familiar. Cloud SQL supports most MySQL statements and functions even stored procedures, triggers and views. It brings the benefits of Cloud economics in the form of flexible pricing. You can pay for what you use. What do we mean by that? GCP manages the MySQL Instance for you. This means things like backup and replication, it's on the Cloud so you can connect to it from anywhere. You can assign it a static IP address, and you can use typical SQL connector libraries. Because it's behind the Google firewall it's fast. You can place your Cloud SQL Instance in the same region as your App Engine or Compute Engine applications and get great bandwidth. Also, you get Google Security. Cloud SQL resides in secure Google datacenters.
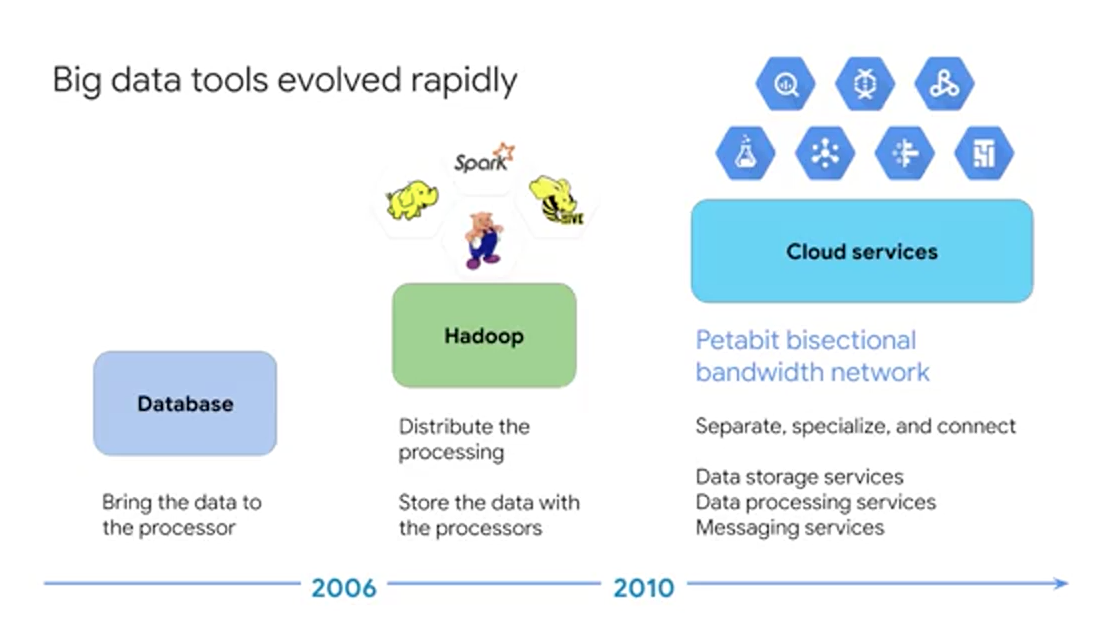
But how will we compute these recommendations in the first place? Where would we be doing the compute? Let's review where big data computations have been done historically and even today. Before 2006, big data meant big databases. Database design came from a time when storage was relatively cheap and processing was expensive. So it made sense to copy the data from its storage location to the processor to perform data processing, and then the result would be copied back to storage. Around 2006, distributed processing of big data became practical with Hadoop. The idea behind Hadoop is to create a cluster of computers and leveraged distributed processing, HDFS. The Hadoop Distributed File System, stored the data on machines in the cluster, and MapReduce provided distributed processing of this data. A whole ecosystem of Hadoop- related software grew up around Hadoop, including Hive, Pig and Spark. Around 2010, BigQuery was released which was the first of many big data services developed by Google. Around 2015, Google launched Cloud Dataproc which provides a managed service for creating Hadoop and Spark clusters, and managing data processing workloads.
The other piece of our system is a software that runs on Hadoop. The software in this case is to train a machine learning model for creating housing recommendations. In this case we used SparkML which is part of ApacheSpark. ApacheSpark is an open source software project that provides a high-performance analytics engine for processing batch and streaming data. Spark can be up to 100 times faster than equivalent Hadoop jobs because it leverages in-memory processing. Spark also provides a couple of abstractions for dealing with data including what are called RDDs, or Resilient Distributed Datasets and DataFrames.
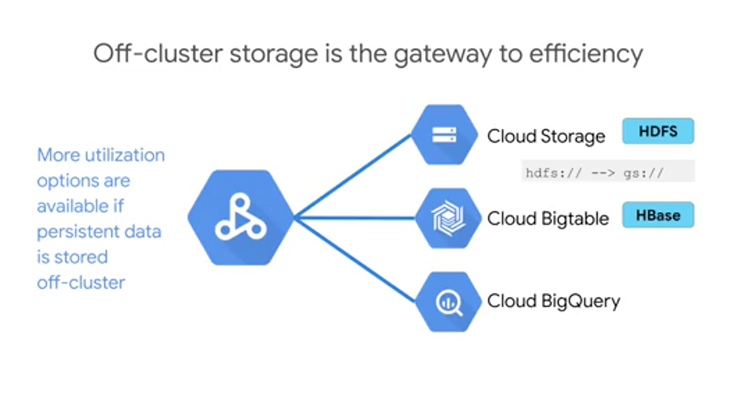
So storing your data off cluster, means that you can process this data not just with Spark from Data-proc but also from all these other products. Not to mention, storing it off cluster in GCS is generally cheaper, since: a, disks attached to computer instances are expensive in and of themselves and b, if your data are off cluster, you'd get to shutdown the computer nodes when you're not using them. You can lift-and-shift your existing Hadoop and Spark workloads, by simply replacing HDFS:// URLs with GS:// URLs. You can connect Cloud Data-proc to Google Cloud Storage and unlock the benefits of both scale and cloud economics. You get to provision a cluster per job if you want to, and shut the cluster down when you're done. Lastly, your clusters are customizable, which could include autoscaling and preemptible VMs so that you get cost savings.