Introduction to Machine Learning in Production
Overview of the ML Lifecycle and Deployment
Steps of an ML Project
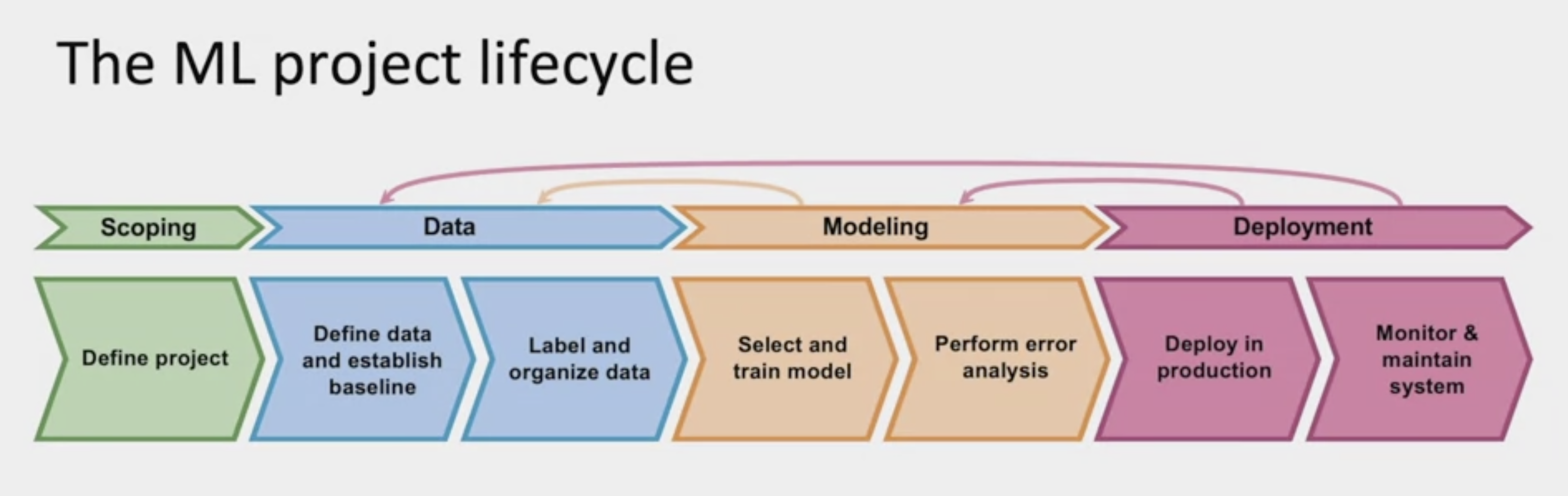
First is scoping, in which you have to define the project or decide what to work on. What exactly do you want to apply Machine Learning to, and what is X and what is Y. After having chosen the project, you then have to collect data or acquire the data you need for your algorithm. This includes defining the data and establishing a baseline, and then also labeling and organizing the data. There are some best practices for this that are non-intuitive that you learn more about later in this week. After you have your data, you then have to train the model. During the model phase, you have to select and train the model and also perform error analysis. You might know that Machine Learning is often a highly iterative task. During the process of error analysis, you may go back and update the model, or you may also go back to the earlier phase and decide you need to collect more data as well.
Deployment
Key Challenges
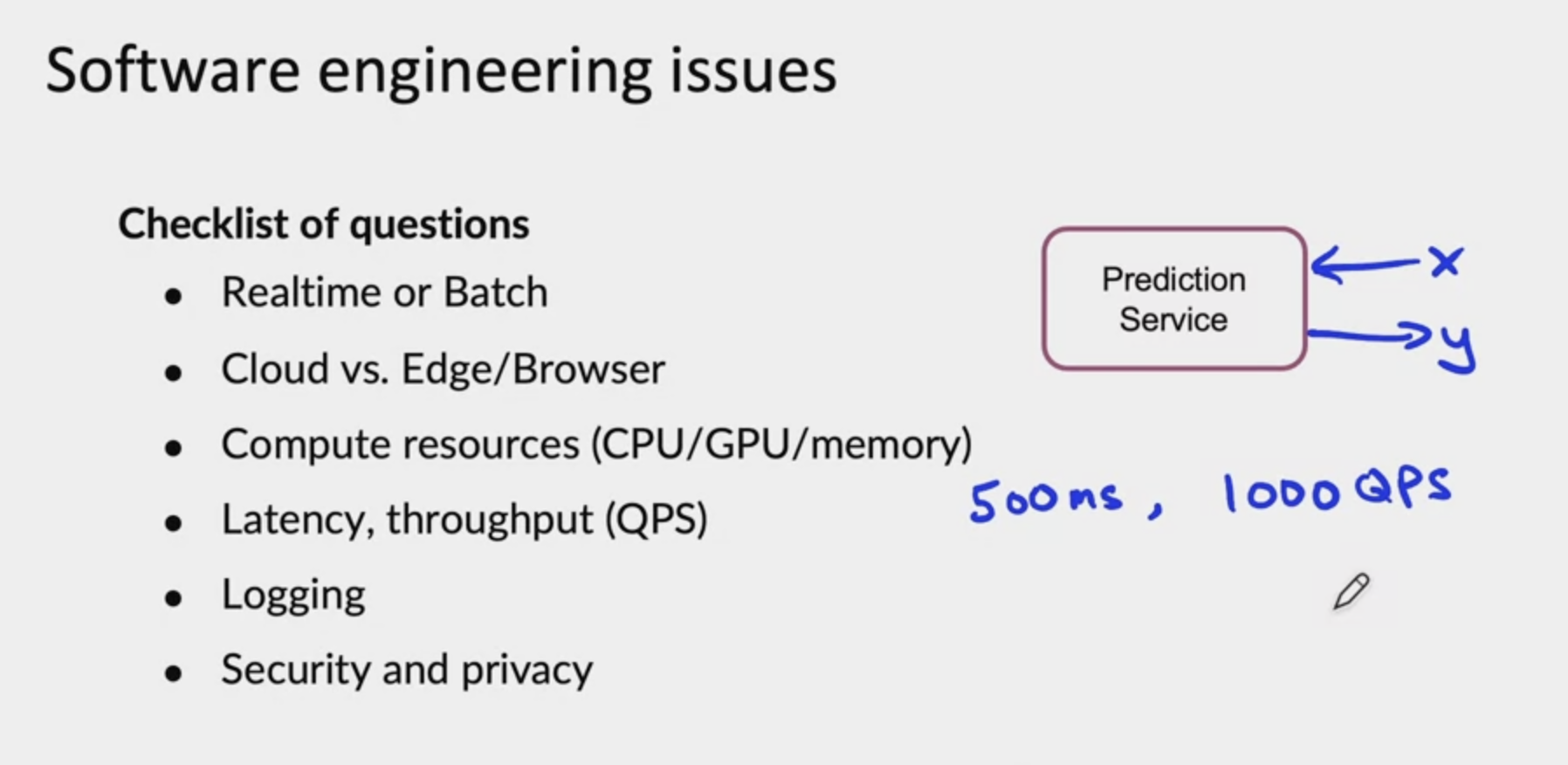
There are two major categories of challenges in deploying a machine learning model. First, are the machine learning or the statistical issues, and second, are the software engineering issues. Let's start with both of these so that you can understand what you need to do to make sure that you have a successful deployment of your system. One of the challenges of a lot of deployments is, concept drift and, data drift. Loosely, this means what if your data changes after your system has already been deployed?
Because the data has changed, such as the language changes or maybe people are using a brand new model of smartphone which has a different microphone, so the audio sounds different, then, the performance of a speech recognition system can degrade. It's important for you to recognize how the data has changed, and if you need to update your learning algorithm as a result. When data changes, sometimes it is a gradual change, such as the English language which does change, but changes very slowly with new vocabulary introduced at a relatively slow rate. Sometimes data changes very suddenly where there's a sudden shock to a system. For example, when COVID-19 the pandemic hit, a lot of credit card fraud systems started to not work because the purchase patterns of individuals suddenly changed. Many people that did relatively little online shopping suddenly started to use much more online shopping. So the way that people were using credit cards changed very suddenly, and his actually tripped up a lot of anti fraud systems. This very sudden shift to the data distribution meant that many machine learning teams were scrambling a little bit at the start of COVID to collect new data and retrain systems in order to make them adapt to this very new data distribution. Sometimes the terminology of how to describe these data changes is not used completely consistently, but sometimes the term data drift is used to describe if the input distribution x changes.
Another example of Concept drift, let's say that x is the size of a house, and y is the price of a house, because you're trying to estimate housing prices. If because of inflation or changes in the market, houses may become more expensive over time. The same size house, will end up with a higher price. That would be Concept drift. Maybe the size of houses haven't changed, but the price of a given house changes. Whereas data drift would be if, say, people start building larger houses, or start building smaller houses and thus the input distribution of the sizes of houses actually changes over time. When you deploy a machine learning system, one of the most important tasks, will often be to make sure you can detect and manage any changes. Including both Concept drift, which is when the definition of what is y given x changes. As well as Data drift, which is if the distribution of x changes, even if the mapping from x or y does not change
To summarize, deploying a system requires two broad sets of tasks: there is writing the software to enable you to deploy the system in production. There is what you need to do to monitor the system performance and to continue to maintain it, especially in the face of concepts drift as well as data drift. One of the things you see when you're building machine learning systems is that the practices for the very first deployments will be quite different compared to when you are updating or maintaining a system that has already previously been deployed. I know that to some engineers that view deploying the machine learning model as getting to the finish line. Unfortunately, I think the first deployment means you may be only about halfway there, and the second half of your work is just starting only after your first deployment, because even after you've deployed there's a lot of work to feed the data back and maybe to update the model, to keep on maintaining the model even in the face of changes to the data
Deployment Patterns

One type of deployment is if you are offering a new product or capability that you had not previously offered. For example, if you're offering a speech recognition service that you have not offered before, in this case, a common design pattern is to start up a small amount of traffic and then gradually ramp it up. A second common deployment use case is if there's something that's already being done by a person, but we would now like to use a learning algorithm to either automate or assist with that task. For example, if you have people in the factory inspecting smartphones scratches, but now you would like to use a learning algorithm to either assist or automate that task. The fact that people were previously doing this gives you a few more options for how you deploy. And you see shadow mode deployment takes advantage of this. And finally, a third common deployment case is if you've already been doing this task with a previous implementation of a machine learning system, but you now want to replace it with hopefully an even better one. In these cases, two recurring themes you see are that you often want a gradual ramp up with monitoring. In other words, rather than sending tons of traffic to a maybe not fully proven learning algorithm, you may send it only a small amount of traffic and monitor it and then ramp up the percentage or amount of traffic. And the second idea you see a few times is rollback. Meaning that if for some reason the algorithm isn't working, it's nice if you can revert back to the previous system if indeed there was an earlier system.
Canary Deployment
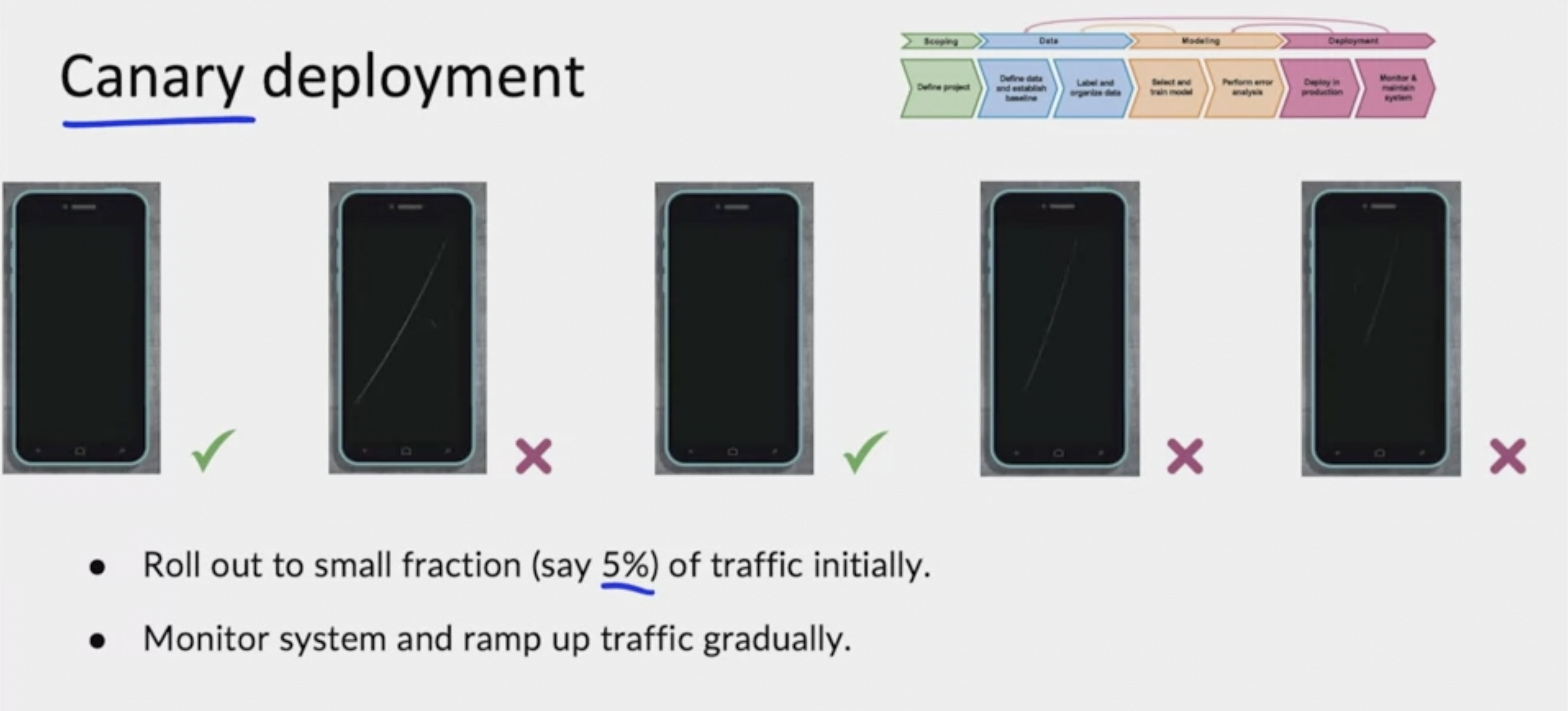
When you are ready to let a learning algorithm start making real decisions, a common deployment pattern is to use a canary deployment. So there's a phone, algorithm says it's okay, rejects that, says that's okay, rejects that, rejects that. And in a canary deployments you would roll out to a small fraction, maybe 5%, maybe even less of traffic initially and start let the algorithm making real decisions. But by running this on only a small percentage of the traffic, hopefully, if the algorithm makes any mistakes it will affect only a small fraction of the traffic. And this gives you more of an opportunity to monitor the system and ramp up the percentage of traffic it gets only gradually and only when you have greater confidence in this performance. The phrase canary deployment is a reference to the English idiom or the English phrase canary in a coal mine, which refers to how coal miners used to use canaries to spot if there's a gas leak. But with canary the deployment, hopefully this allows you to spot problems early on before there are maybe overly large consequences to a factory or other context in which you're deploying your learning algorithm.
Blue Green Deployment
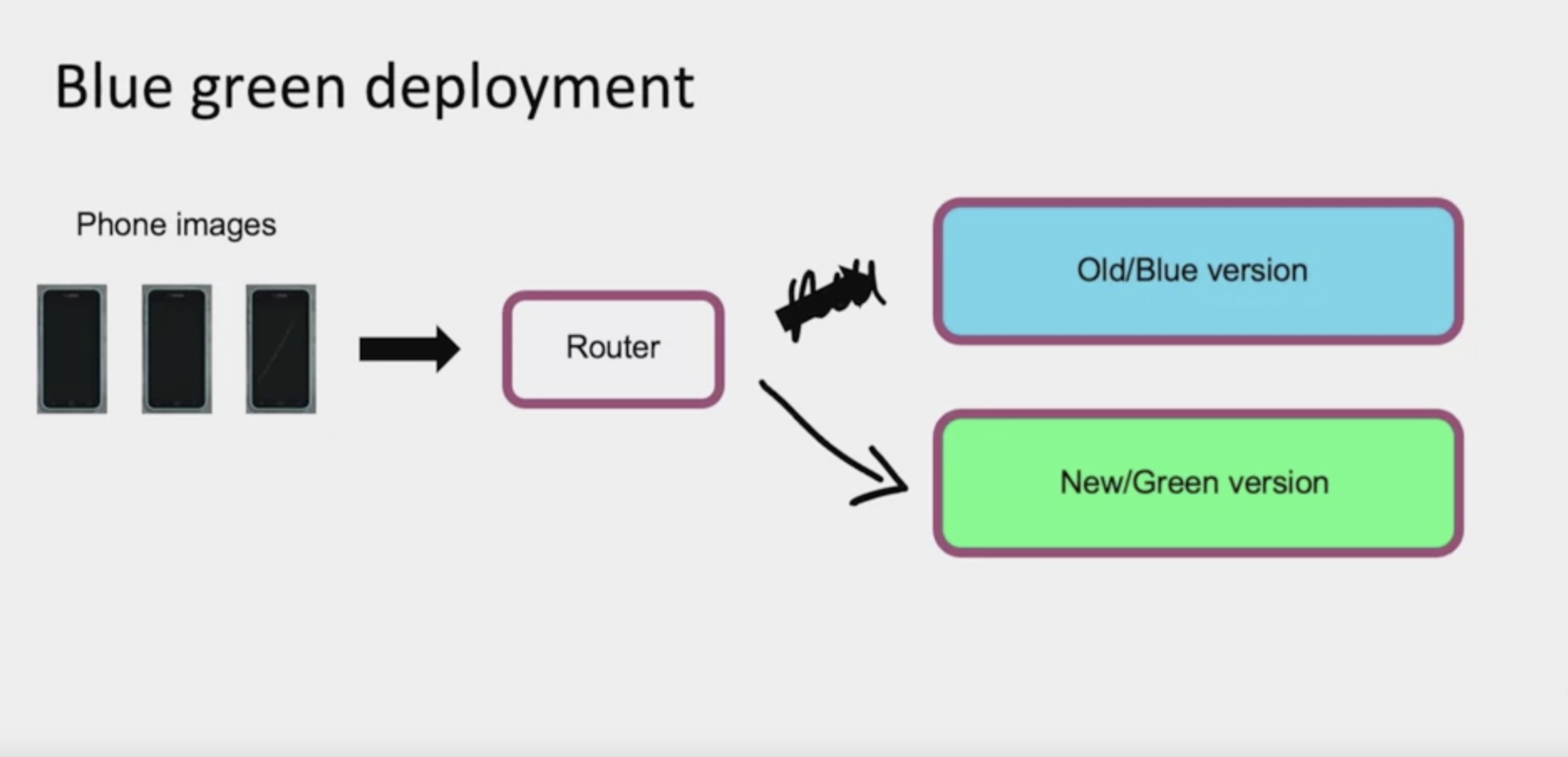
Another deployment pattern that is sometimes used is a blue green deployment. Let me explain with the picture. Say you have a system, a camera software for collecting phone pictures in your factory. These phone images are sent to a piece of software that takes these images and routes them into some visual inspection system. In the terminology of a blue green deployments, the old version of your software is called the blue version and the new version, the Learning algorithm you just implemented is called the green version. In a blue green deployment, what you do is have the router send images to the old or the blue version and have that make decisions. And then when you want to switch over to the new version, what you would do is have the router stop sending images to the old one and suddenly switch over to the new version. So the way the blue green deployment is implemented is you would have an old prediction service may be running on some sort of service. You will then spin up a new prediction service, the green version, and you would have the router suddenly switch the traffic over from the old one to the new one. The advantage of a blue green deployment is that there's an easy way to enable rollback. If something goes wrong, you can just very quickly have the router go back reconfigure their router to send traffic back to the old or the blue version, assuming that you kept your blue version of the prediction service running. In a typical implementation of a blue green deployment, people think of switching over the traffic 100% all at the same time. But of course you can also use a more gradual version where you slowly send traffic over.
Degrees of Automation
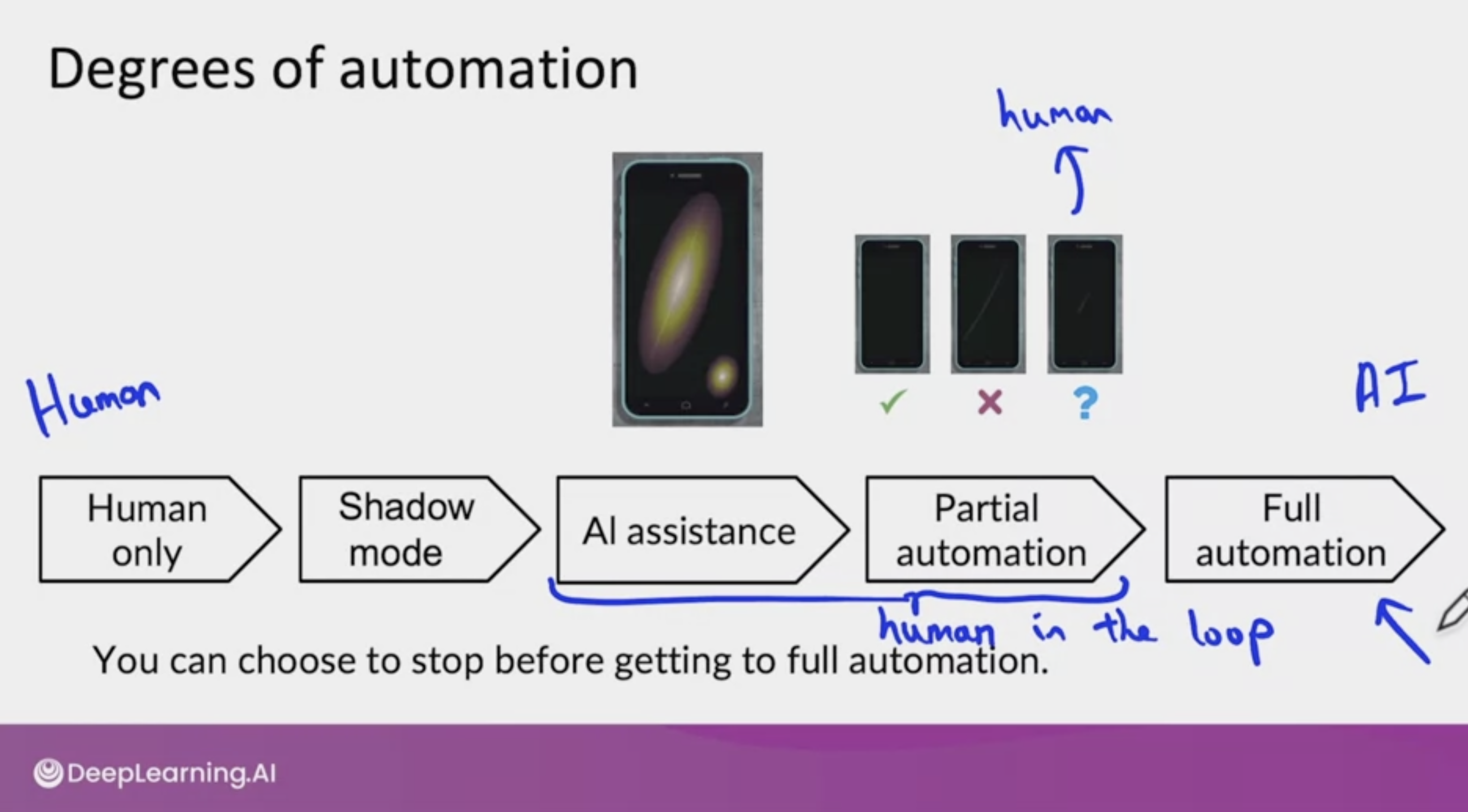
As you can imagine, whether use shadow mode, canary mode, blue green, or some of the deployment pattern, quite a lot of software is needed to execute this. MLOps tools can help with implementing these deployment patterns or you can implement it yourself. One of the most useful frameworks I have found for thinking about how to deploy a system is to think about deployment not as a 0, 1 is either deploy or not deploy, but instead to design a system thinking about what is the appropriate degree of automation.
For example, in visual inspection of smartphones, one extreme would be if there's no automation, so the human only system. Slightly mode automated would be if your system is running a shadow mode. So your learning algorithms are putting predictions, but it's not actually used in the factory. So that would be shadow mode. A slightly greater degree of automation would be AI assistance in which given a picture like this of a smartphone, you may have a human inspector make the decision. But maybe an AI system can affect the user interface to highlight the regions where there's a scratch to help draw the person's attention to where it may be most useful for them to look. The user interface or UI design is critical for human assistance. But this could be a way to get a slightly greater degree of automation while still keeping the human in the loop. And even greater degree of automation maybe partial automation, where given a smartphone, if the learning algorithm is sure it's fine, then that's its decision. It is sure it's defective, then we just go to algorithm's decision. But if the learning algorithm is not sure, in other words, if the learning algorithm prediction is not too confident, 0 or 1, maybe only then do we send this to a human. So this would be partial automation.
Where if the learning algorithm is confident of its prediction, we go the learning algorithm. But for the hopefully small subset of images where the algorithm is not sure we send that to a human to get their judgment. And the human judgment can also be very valuable data to feedback to further train and improve the algorithm. I find that this partial automation is sometimes a very good design point for applications where the learning algorithms performance isn't good enough for full automation. And then of course beyond partial automation, there is full automation where we might have the learning algorithm make every single decision. So there is a spectrum of using only human decisions on the left, all the way to using only the AI system's decisions on the right. And many deployment applications will start from the left and gradually move to the right. And you do not have to get all the way to full automation. You could choose to stop using AI assistance or partial automation or you could choose to go to full automation depending on the performance of your system and the needs of the application.
On this spectrum both AI assistance and partial automation are examples of human in the loop deployments. I find that the consumer Internet applications such as if you run a web search engine, write online speech recognition system. A lot of consumer software Internet businesses have to use full automation because it's just not feasible to someone on the back end doing some work every time someone does a web search or does the product search. But outside consumer software Internet, for example, inspecting things and factories. They're actually many applications where the best design point maybe a human in the loop deployments rather than a full automation deployment. In this video, you saw a few patterns of deployments, such as a shadow mode deployment, canary deployment, blue green deployment. And you also saw how you can pick the most appropriate degree of automation depending on your application, which could be a human in the loop deployments or full automation.
Monitoring
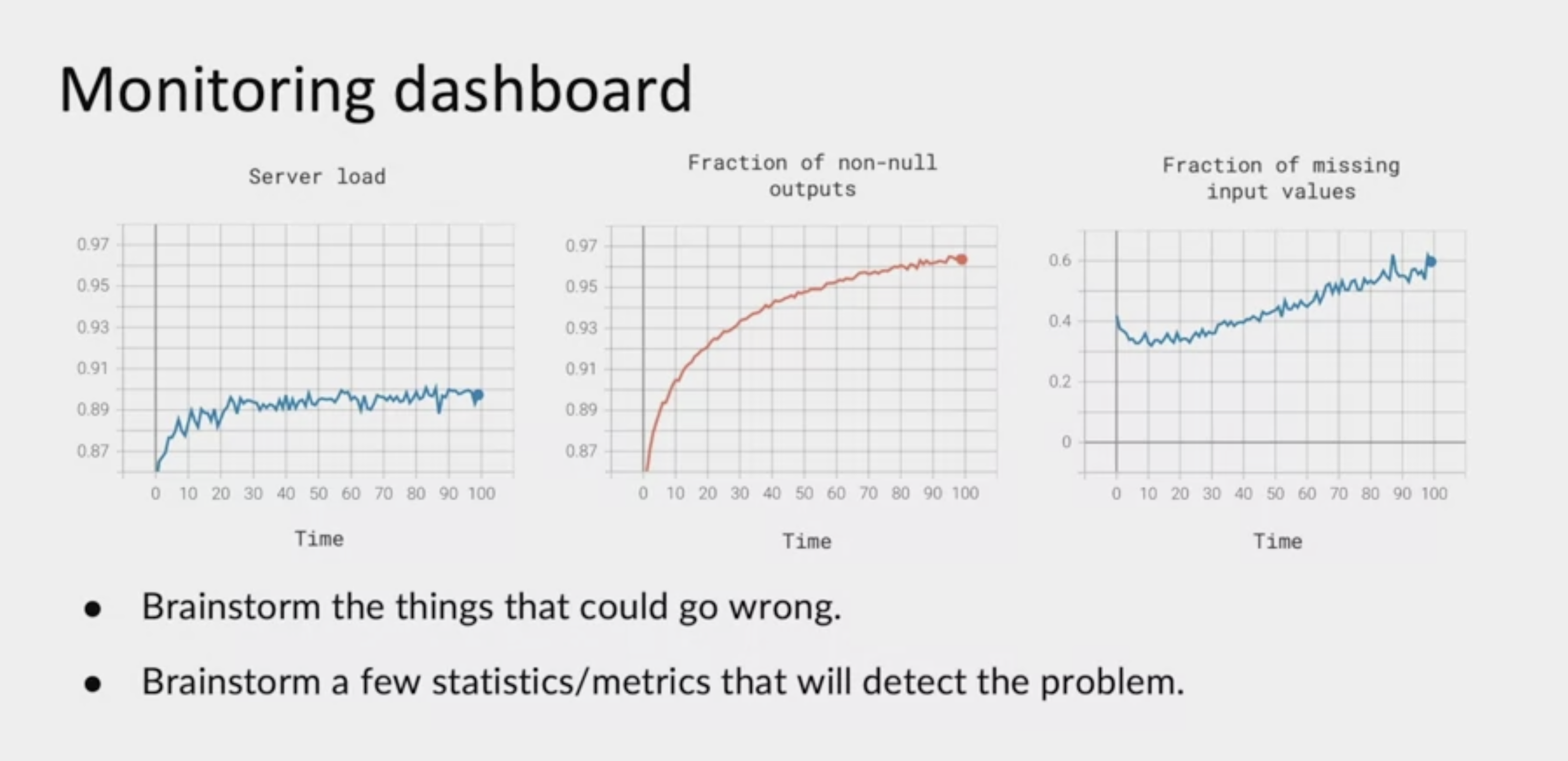
The most common way to monitor a machine learning system is to use a dashboard to track how it is doing over time. Depending on your application, your dashboards may monitor different metrics. For example, you may have one dashboard to monitor the server load, or a different dashboards to monitor diffraction of non-null outputs. Sometimes a speech recognition system output is null when the things that users didn't say anything. If this changes dramatically over time, it may be an indication that something is wrong, or one common one I've seen for a lot of structured data task is monitoring the fraction of missing input values. If that changes, it may mean that something has changed about your data. When you're trying to decide what to monitor, my recommendation is that you sit down with your team and brainstorm all the things that could possibly go wrong. Then you want to know about if something does go wrong. For all the things that could go wrong, brainstorm a few statistics or a few metrics that will detect that problem. For example, if you're worried about user traffic spiking, causing the service to become overloaded, then server loads maybe one metric, you could track and so on for the other examples here.

Here are some examples of metrics our views or I've seen others use on a variety of projects. First are the software metrics, such as memory, compute, latency, throughput, server load, things that help you monitor the health of your software implementation of the prediction service or other pieces of software around your learning algorithm. But these software metrics will help you make sure that your software is running well. Many MLOps tools will come over the bouts already tracking these software metrics. In addition to the software metrics, I would often choose other metrics that help monitor the statistical health or the performance of the learning algorithm.
Broadly, there are two types of metrics you might brainstorm around. One is input metrics, which are metrics that measure has your input distribution x change. For example, if you are building a speech recognition system, you might monitor the average input length in seconds of the length for the audio clip fed to your system. You might monitor the average input volume. If these change for some reason, that might be something you'll once to take a look at just to make sure this hasn't hurt the performance of your algorithm. I mentioned just now, number or percentage of missing values is a very common metric. When using structured data, some of which may have missing values, or for the manufacturing visual inspection example, you might monitor average image brightness if you think that lighting conditions could change, and you want to make sure you know if it does, so you can brainstorm different metrics to see if your input distribution x might have changed.
A second set of metrics that help you understand if your learning algorithm is performing well are output metrics. Such as, how often does your speech recognition system return null, the empty string, because the things the user doesn't say anything, or if you have built a speech recognition system for web search using voice, you might decide to see how often does the user do two very quick searches in a row with substantially the same input. That might be a sign that you misrecognize their query the first time round. It's an imperfect signal but you could try this metric and see if it helps. Or you could monitor the number of times the user first try to use the speech system and then switches over to typing, that could be a sign that the user got frustrated or gave up on your speech system and could indicate degrading performance.
Of course, for web search, you would also use maybe very course metrics like click-through rate or CTR, just to make sure that the overall system is healthy. These output metrics can help you figure out if either your learning algorithm, output y has changed in some way, or if something that comes even after your learning algorithms output, such as the user's switching over to typing has changed in some significant way.
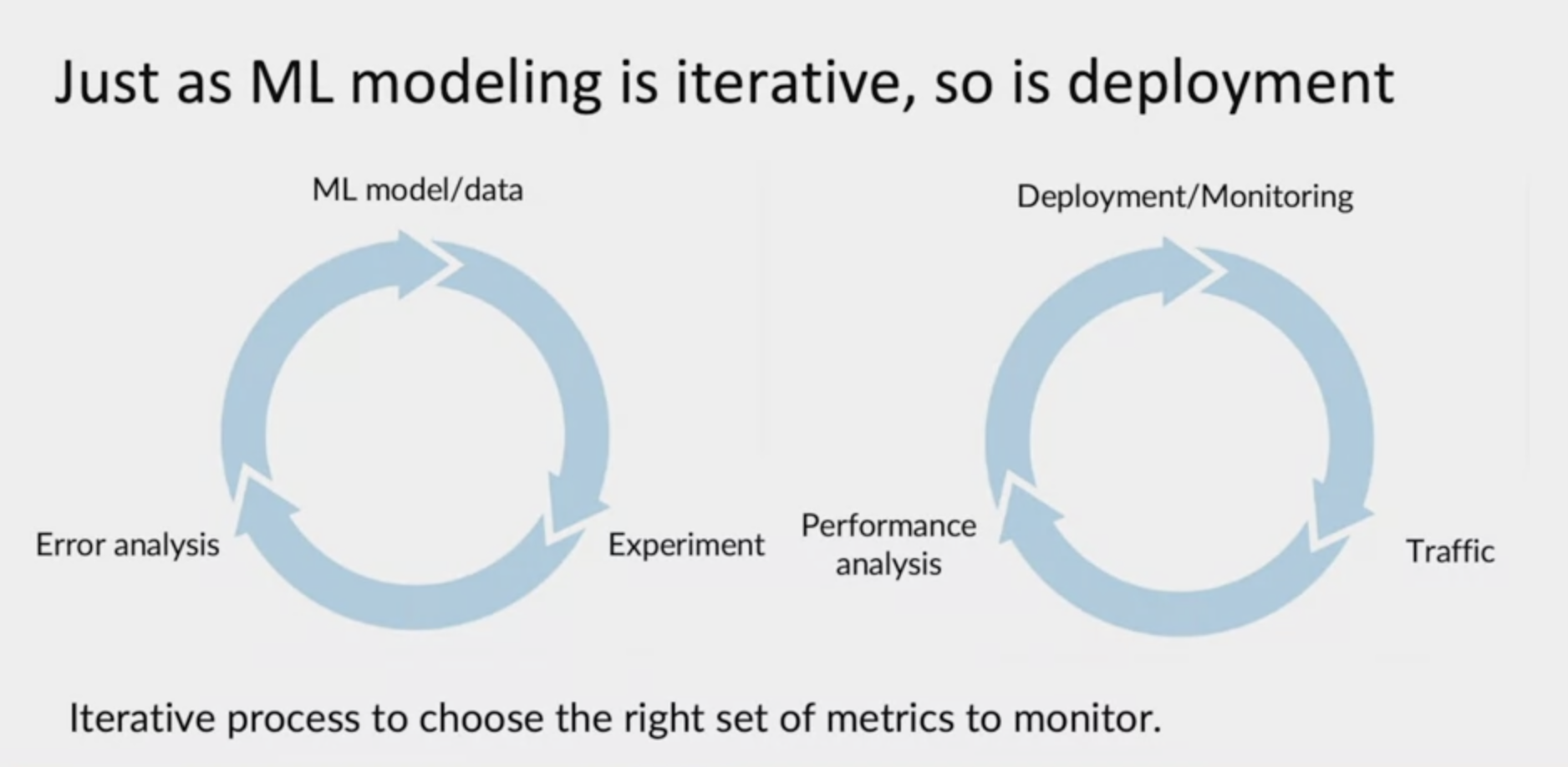
Because input and output metrics are application specific, most MLOps tools will need to be configured specifically to track the input and output metrics for your application. You may already know that machine learning modeling is a highly iterative process, so as deployment. Take modeling, you would come up with a machine learning model and some data, train the model, that's an experiment. Then do error analysis and use the error analysis to go back to figure out how to improve the model or your data and is by iterating through this loop multiple times that you then hopefully gets a good model. I encourage you to think of deployments as an iterative process as well. When you get your first deployments up and running and put in place a set of monitoring dashboards. But that's only the start of this iterative process.
A running system allows you to get real user data or real traffic. It is by seeing how your learning algorithm performs on real data on real traffic that, that allows you to do performance analysis, and this in turn helps you to update your deployment and to keep on monitoring your system. In my experience, it usually takes a few tries to converge to the right set of metrics to monitor. Sometimes have deploy the machine learning system, and it's not uncommon for you to deploy machine learning system with an initial set of metrics only to run the system for a few weeks and then to realize that something could go wrong with it that you hadn't thought of before and into pick a new metric to monitor. Or for you to have some metric that you monitor for a few weeks and then decide they're just metric, hardly ever changes in does is inducible, and to get rid of that metric in favor of focusing attention on something else. After you've chosen a set of metrics to monitor, common practice would be to set thresholds for alarms.
Just like almost all software needs some level of maintenance as well. When a model needs to be updated, you can either retrain it manually, where in Engineer, maybe you will retrain the model perform error analysis and the new model and make sure it looks okay before you push that to deployment. Or you could also put in place a system where there is automatic retraining. Today, manual retraining is far more common than automatically training for many applications developers are reluctant to learning algorithm be fully automatic in terms of deciding to retrain and pushing new model to production, but there are some applications, especially in consumer software Internet, where automatically training does happen.
But the key takeaways are that it is only by monitoring the system that you can spot if there may be a problem that may cause you to go back to perform a deeper error analysis, or that may cause you to go back to get more data with which you can update your model so as to maintain or improve your system's performance